-

-
-
Products
- Industries
-
Ordering
Food Grocery Home Services -
Delivery & Dispatch
Pick Up & Delivery Courier Delivery 3PL Delivery Dispatch -
Consultation
Telemedicine Fitness Legal Consultation -
Mobility
Taxi Software App Like Uber Car Rental -
Customer Engagement
Conversational support WhatsApp Marketing Customer Acquisition -
Sales Engagement
Inbound Sales Pipeline Management Sales Performance Analytics
Explore All Industries
-
-
Learn
- Partner
- Pricing
-
- Try Now
Blog JW Blog
JW Blog
AWS AutoScaling for Haproxy

Weall have heard of AWS Autoscaling along with AWS Load Balancers. After the launch of AWS Application Load balancer, many cloud users started using AWS ALB having a flexible feature set for their web applications with HTTP and HTTPS traffic, but AWS load balancer is a black-box load balancing solution. Advanced customization of traffic rules is still not possible with AWS load balancers. Haproxy is an open source load balancer proxy for TCP and HTTP applications with customized traffic rules, more control over configuration and security parameters. A few lines of python code helped to achieve AWS autoscaling along with Haproxy. I used the following resources for my application under haproxy:
* n on-demand instances.
* m spot instances in autoscaling group.
Steps followed
1. AMI creation for one on-demand instance.
2. Update Launch template with latest AMI.
3. Autoscaling group with latest launch template.
4. Custom autoscaling Cloudwatch metrics.
5. Updating haproxy config with the cron job.
6. Deployment to all servers using Jenkins.
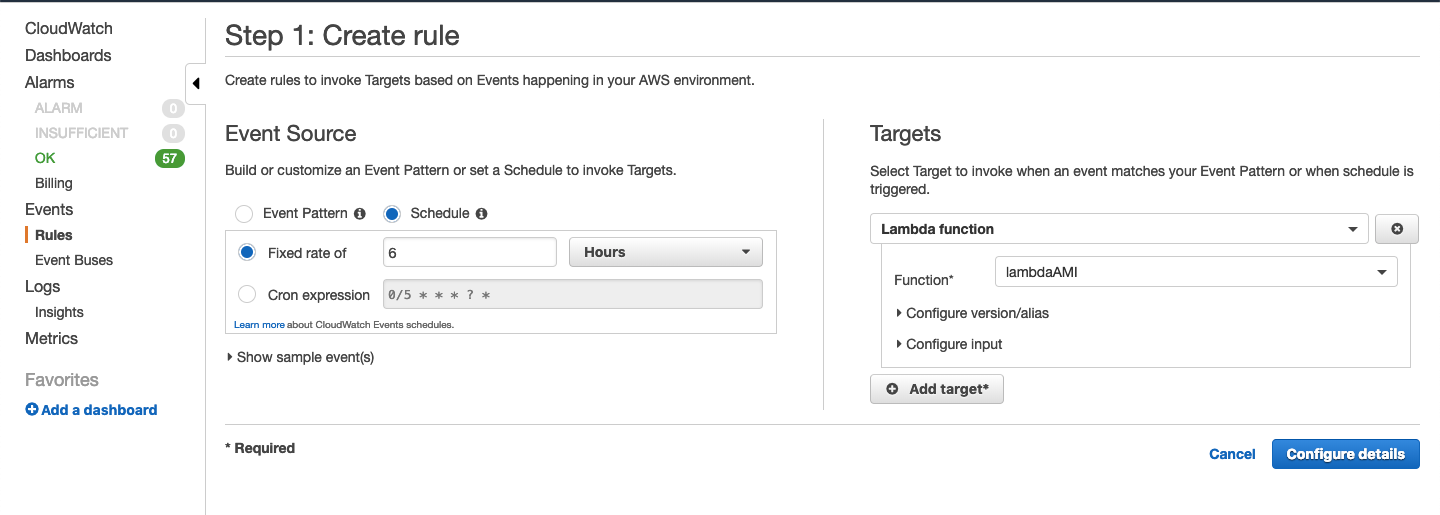
- AMI Creation: Automated AMI creation of one of the on-demand instance with the AMICreationScript added in Lambda. Run this lambda every 6 hours with AWS Cloudwatch rule shown below.
2. Update Launch template: After the AMI creation, we need to update the launch template with the latest AMI as defined herein python UpdateLaunchTemplateScript.

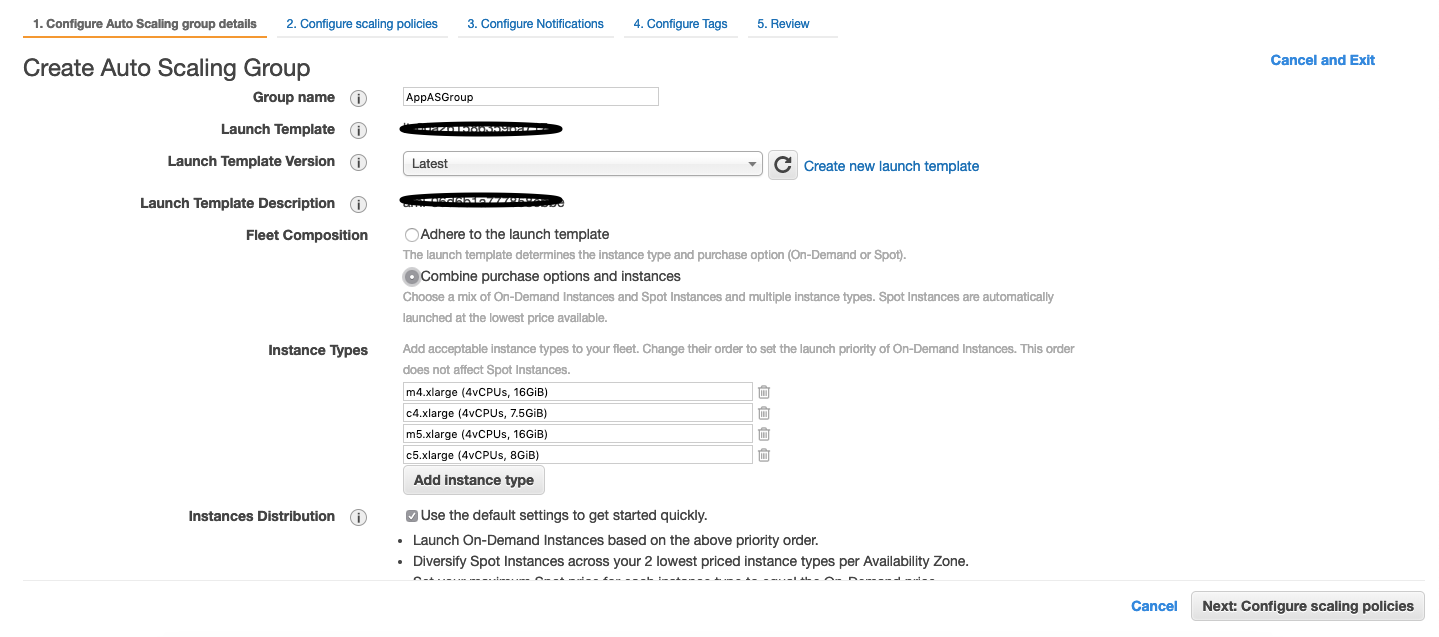
3. Autoscaling group: Once our launch template is updated with the latest AMI, we need to create an autoscaling group ready to launch spot EC2 instances. Adding Auto Scaling Group configuration for more details.
4. Custom CloudWatch Metrics: In order to plot a graph for CPU Utilization of the on-demand EC2 instances along with spot instances running inside AutoScaling group, we need to fetch stats of each of these instances from CloudWatch. Average of combined CPU Utilisation is plotted on AWS CloudWatch as a custom metric. We need to add two CW alarms in order to add scaling IN and OUT options in the Auto Scaling Group. Added CustomCPUMetricScript on Github.
Get CPU utilization of individual instances from CW

Put combined metrics to CW

5. Update Haproxy Configuration: After the scaling has happened, we need to update backend servers in the haproxy configuration file and reload it. In order to update the haproxy config, I have created a template config in /etc/haproxy/ directory. The FetchInstancesScript is creating a new config file from the template, adding updated backend instances to it, validating config, replacing the main config file and reloading haproxy. This script is running every minute in crontab.
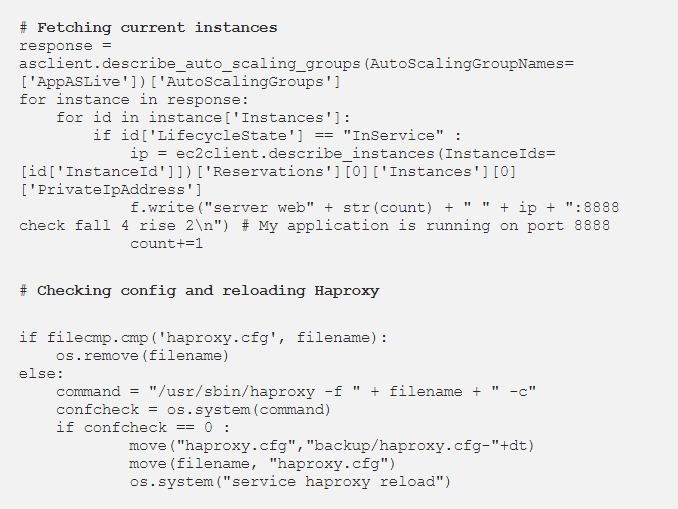
6. Jenkins Deployment: Jenkins is helping us deploying code on each of these servers. A Jenkins pipeline is created at runtime to detach instance from haproxy, build, test and deploy. The script is finding out current instances from autoscaling group and creating Jenkinsfile at runtime. I have added BlueOcean plugin on Jenkins for this beautiful UI.


Author: Vivek Puri
Visit the link to read more from Vivek Puri: https://medium.com/@vivek.puri
Subscribe to stay ahead with the latest updates and entrepreneurial insights!
Share this article:


Subscribe to our newsletter
Get access to the latest industry & product insights.
You may be interested in these articles
-
Jungleworks21st January 2025
How Dark Kitchens Are Changing the Face of the Food Delivery IndustryEver heard about Dark Kitchens? No, no, it’s not some mysterious kitchen.. [..]Read story
-
Jungleworks15th January 2025
Why Proof of Delivery Is Crucial for Logistics and Customer TrustHave you ever faced the frustration of ordering something online, only to be.. [..]Read story
-
Jungleworks14th January 2025
Powering Growth: The Role of Technology in Enterprise SuccessIn today's fast-paced business world, technology is the engine driving growth.. [..]Read story
-
Jungleworks8th January 2025
How Route Optimization Can Reduce Delivery Times and CostsIn today’s fast-paced world, where customers expect quick and efficient.. [..]Read story